Overview
I had the opportunity to build a character detection model using YOLOv11x and the Japanese Classical Character (Kuzushiji) Dataset, so this is a memo of the process.
http://codh.rois.ac.jp/char-shape/
References
Previously, I performed a similar task using YOLOv5. You can check the demo and pre-trained models at the following Spaces.
https://huggingface.co/spaces/nakamura196/yolov5-char
Below is an example of application to publicly available images from the “National Treasure Kanazawa Bunko Documents Database.”

The goal was to improve character detection accuracy by using YOLOv11.
Creating the Dataset
Download the “Japanese Classical Character (Kuzushiji) Dataset” and format it into the format required by YOLO.
The format can be verified at the following location, among others.
https://github.com/ultralytics/hub/tree/main/example_datasets/coco8
Image Size Set to 1280x1280
The following Ultralytics HUB was used.
Below are the training results.

When applied to the test data, some image data showed good accuracy (e.g., “The Tale of Genji” (University of Tokyo General Library collection)),
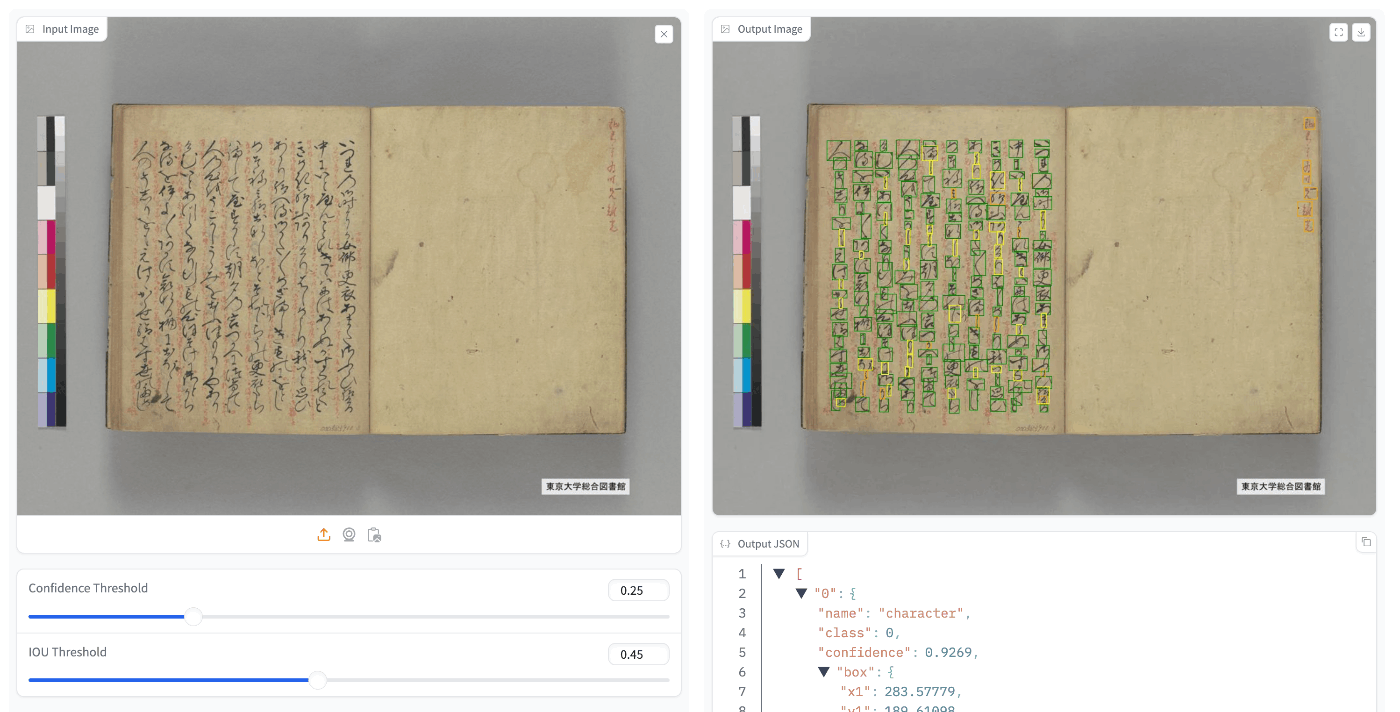
while other image data did not show good accuracy (e.g., “National Treasure Kanazawa Bunko Documents Database”).
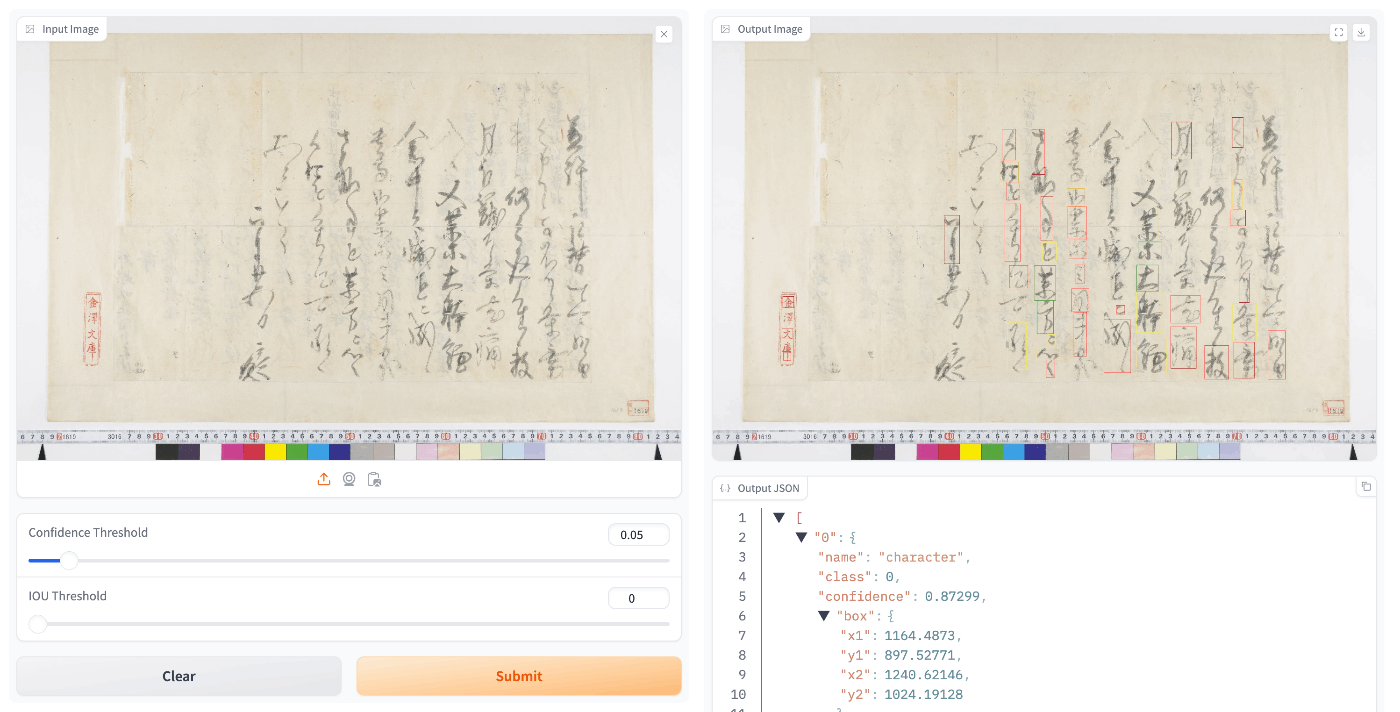
Image Size Set to 640x640
With 10 Epochs
With 10 epochs, the training may not have fully converged.
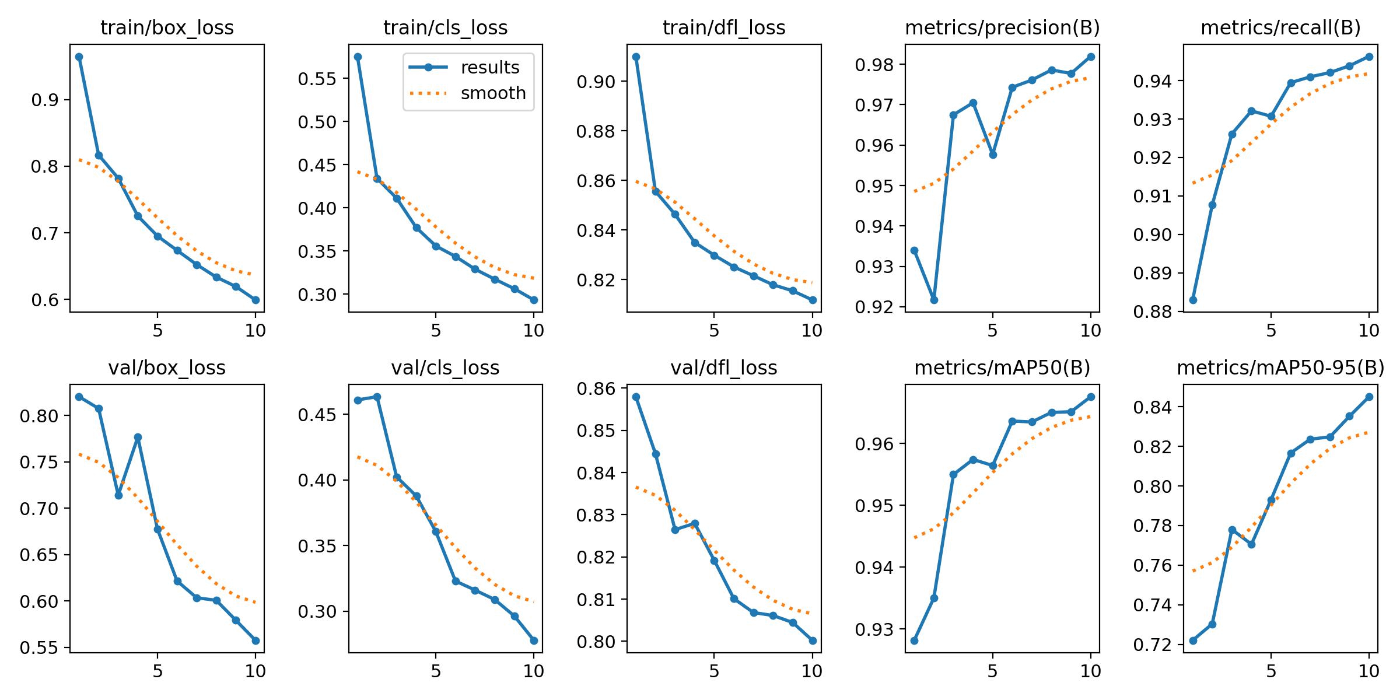
On the other hand, despite the smaller number of epochs, the results on test data appeared better than the 1280x1280 model.
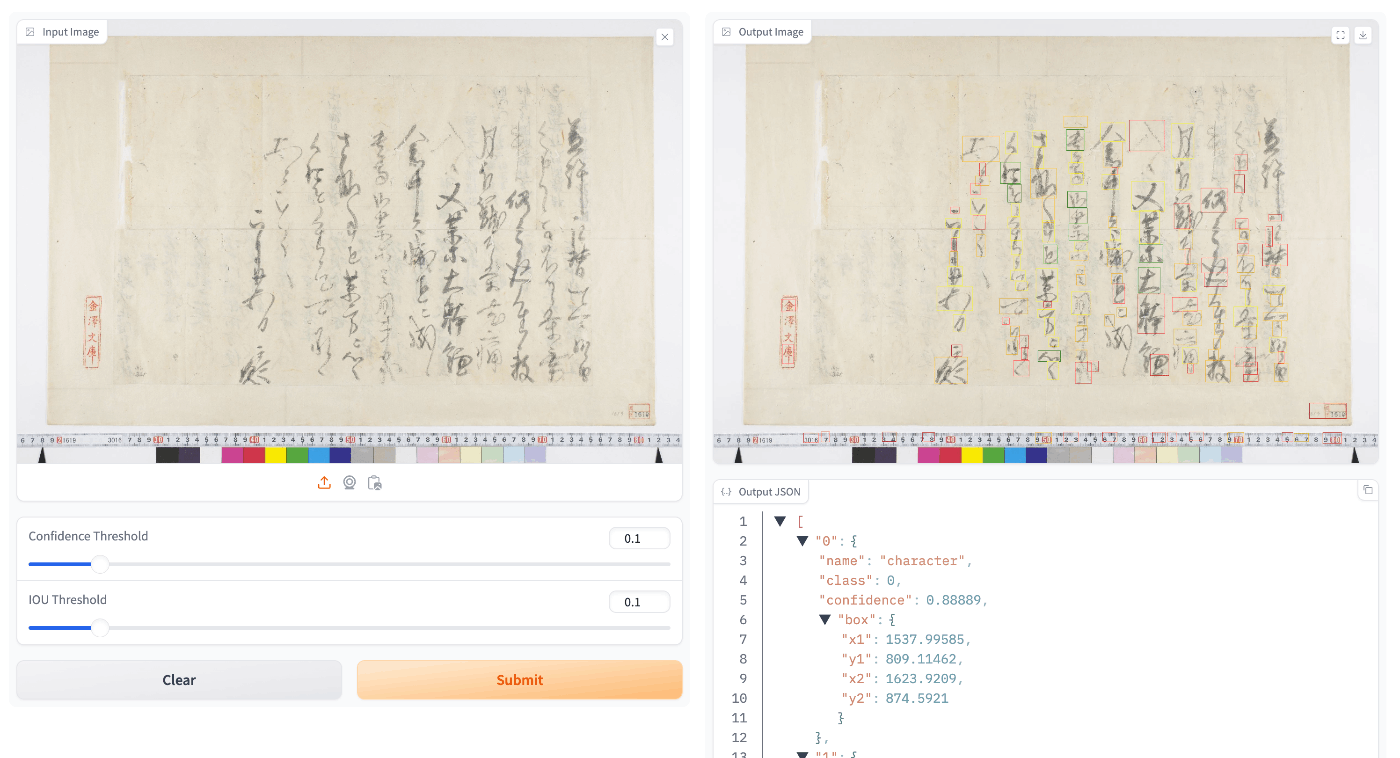
With 100 Epochs
With a batch size of 16 (default), GPU memory utilization was low, and setting it to 32 resulted in an OutOfMemoryError.
With batch size 24:
The results were as follows.
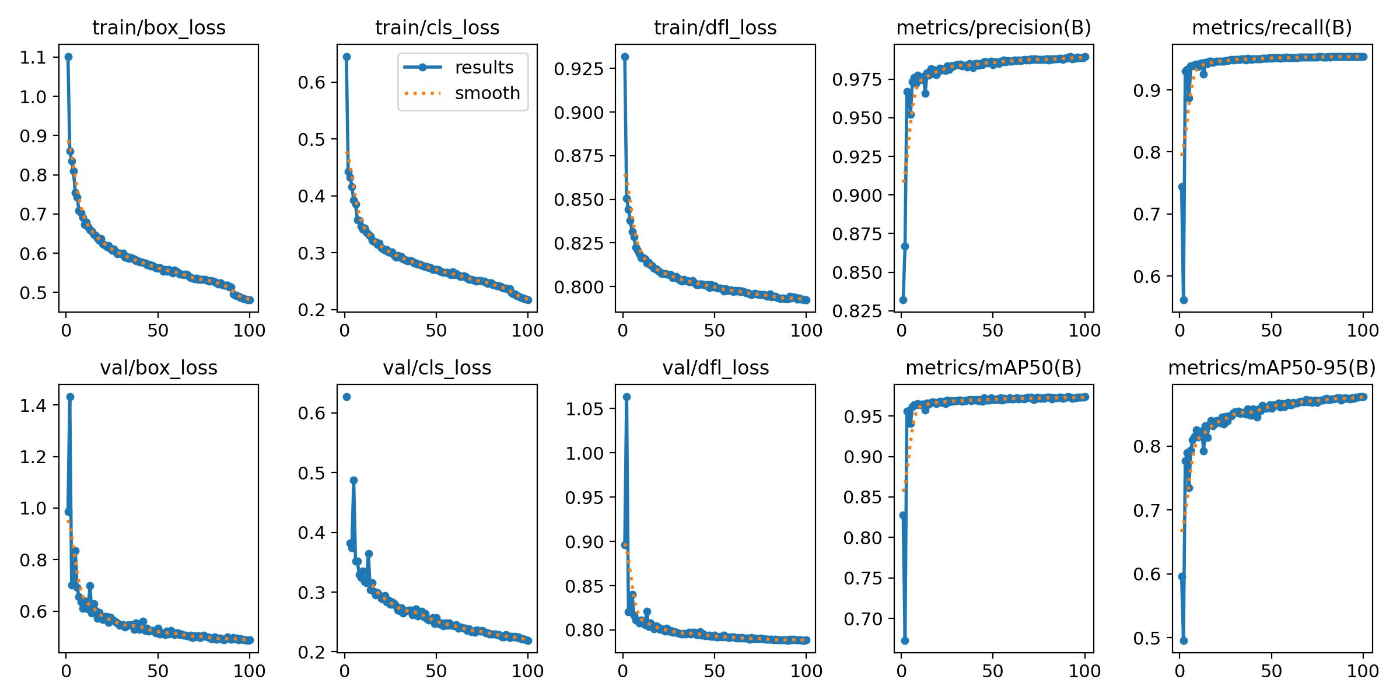
On the test data, the results were as follows.
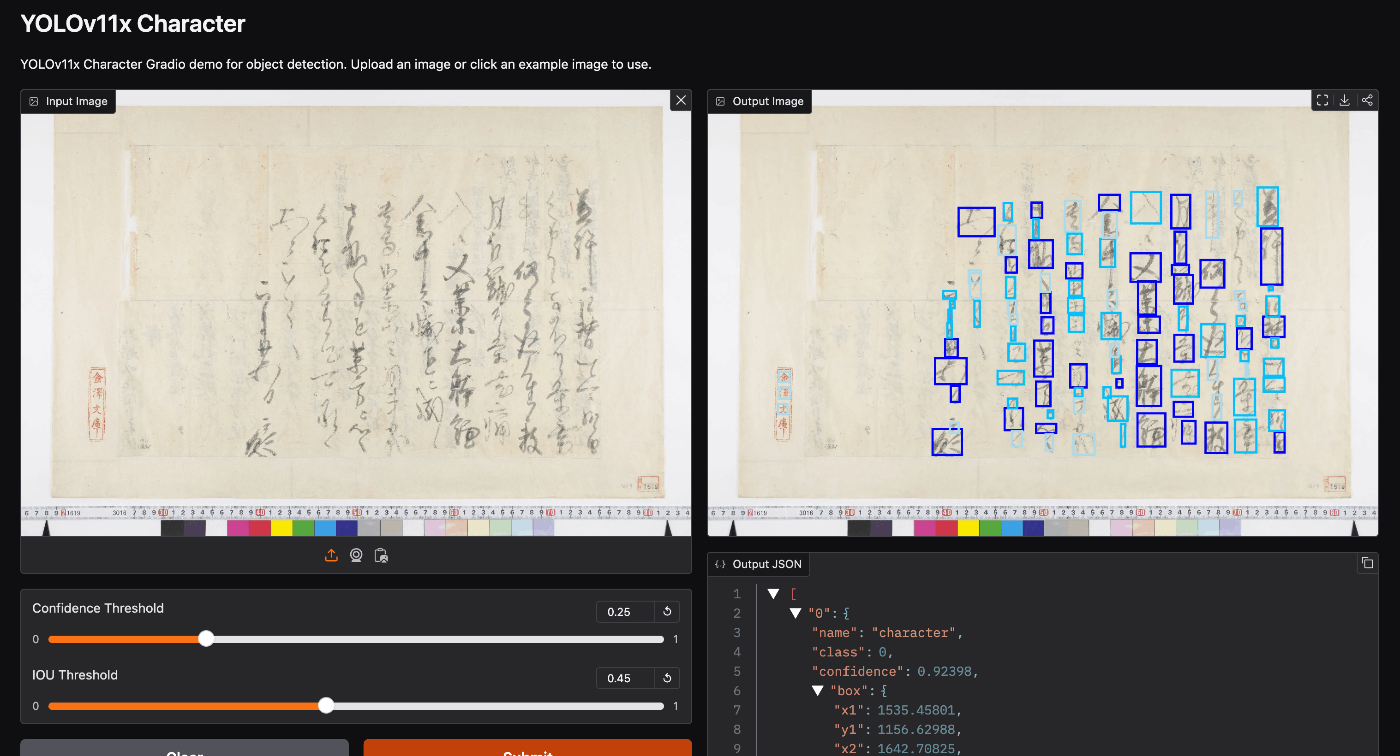
While the accuracy does not appear to have dramatically improved compared to the model built with YOLOv5, detection accuracy seemed to improve compared to the model with image size set to 1280x1280.
Hugging Face
A Space using the built model is published at the following location.
https://huggingface.co/spaces/nakamura196/yolov11x-codh-char
Summary
I hope this serves as a helpful reference for building object detection models using mdx.jp and the Japanese Classical Character Dataset.