Overview
I built a layout extraction model using the NDL-DocL dataset and YOLOv5.
https://github.com/ndl-lab/layout-dataset
https://github.com/ultralytics/yolov5
You can try this model using the following notebook.
This article is a record of the training process above.
Creating the Dataset
The NDL-DocL dataset in Pascal VOC format is converted to YOLO format. For this method, refer to the following article. In addition to the conversion from Pascal VOC format to COCO format, conversion from COCO format to YOLO format was added.
Training
The following page describes how to train on custom data.
https://github.com/ultralytics/yolov5/wiki/Train-Custom-Data
The following notebook also describes the training method.
https://colab.research.google.com/github/ultralytics/yolov5/blob/master/tutorial.ipynb
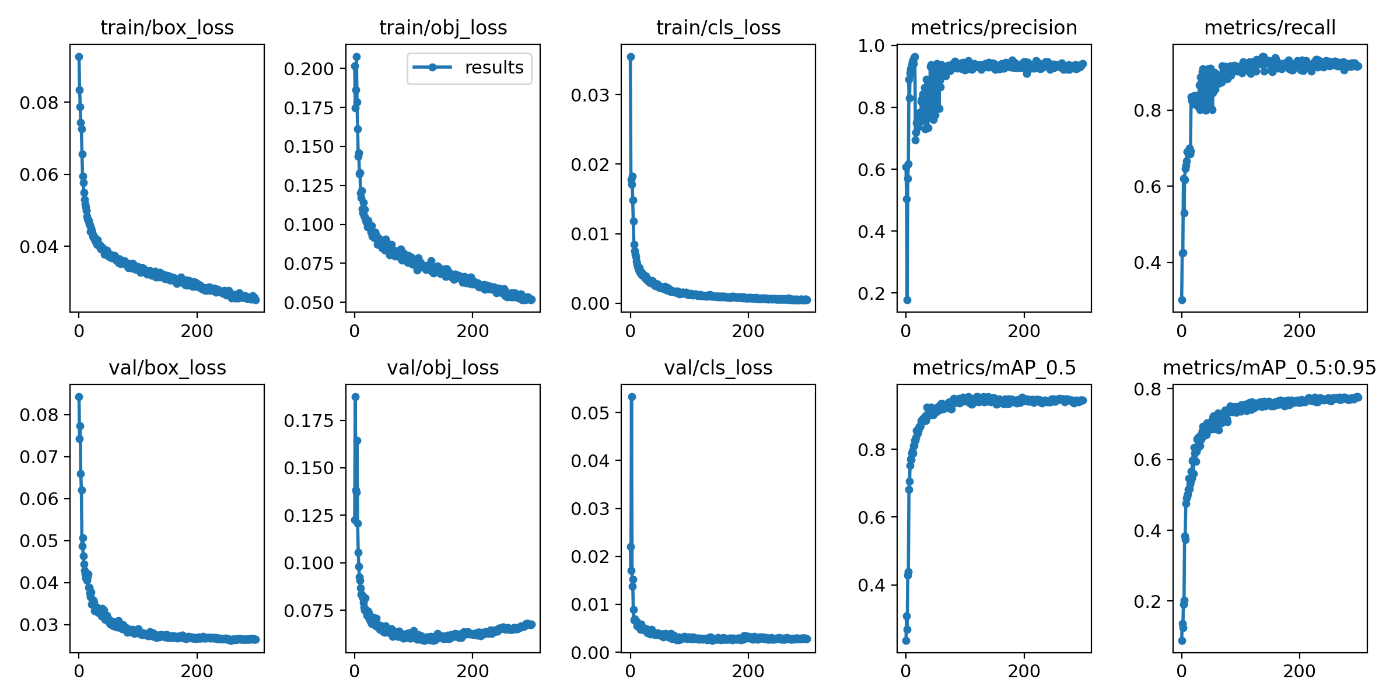
With the input image size set to 1024, batch size to 4, and number of epochs to 300, the following results were obtained. The dataset was split into 80% train, 10% validation, and 10% test.
Inference
As mentioned above, you can try inference using the following notebook.
Below are examples of inference results. Only successfully recognized examples are shown.
“The Tale of Genji” (University of Tokyo collection)

“The Tale of Genji” (Kyoto University collection)

“The Tale of Genji” (Kyushu University collection)

Summary
Based on the layout recognition results, the next step will be to work on character recognition within lines.