Overview
@yuta1984 developed a “WebAssembly-based web port of NDL Kotenseki OCR-Lite”:
https://github.com/yuta1984/ndlkotenocr-lite-web
Using the above repository as a reference, I created a Next.js version:
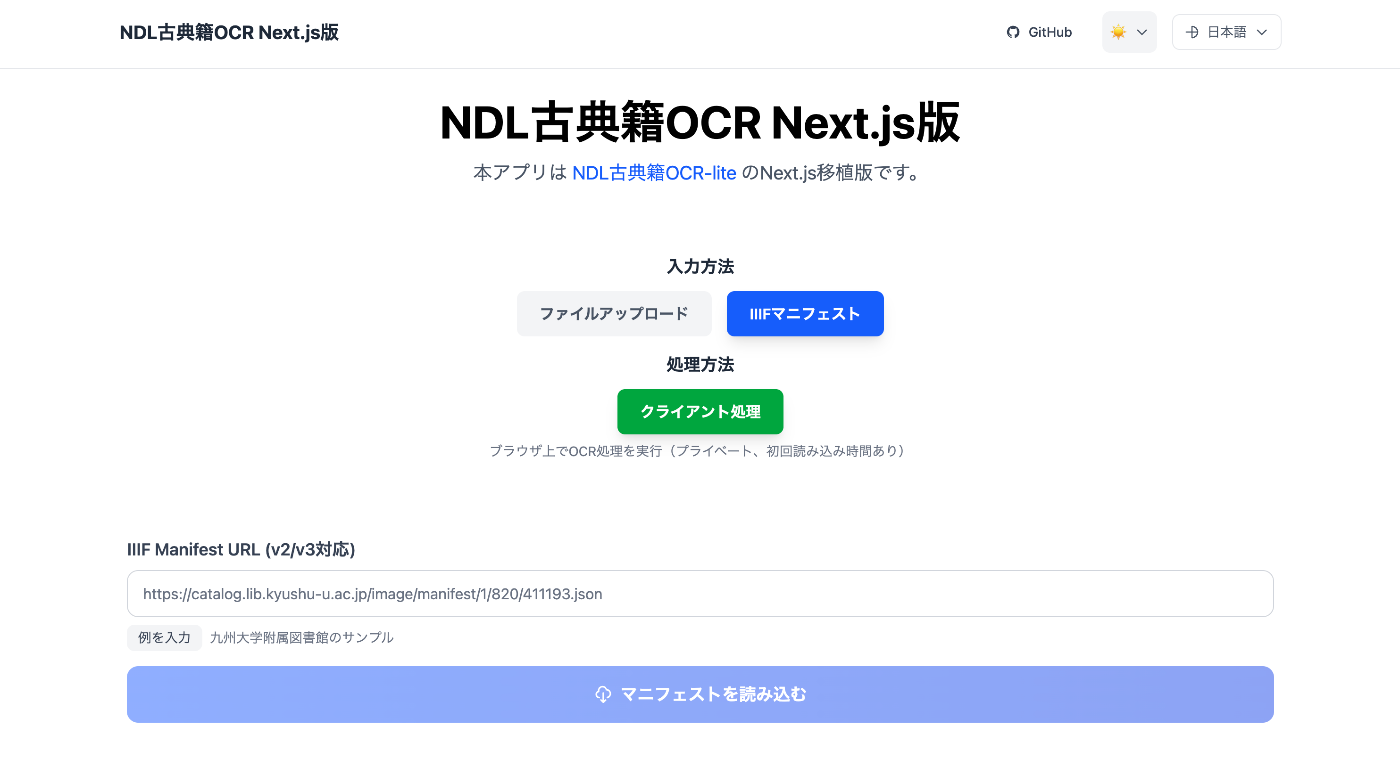
In addition, the following features have been added:
- IIIF manifest file input form
- TEI/XML file download functionality
- Creation of an ODD file for the output format
Usage
As an example, we use the Tale of Genji from the Kyushu University Library:
https://catalog.lib.kyushu-u.ac.jp/image/manifest/1/820/411193.json
After entering the manifest file and clicking the “Load” button, a list of images is displayed as shown below:

Internally, @iiif/parser is used to support both v2 and v3 manifest files.
After pressing the execution button, OCR result text is displayed for each image:
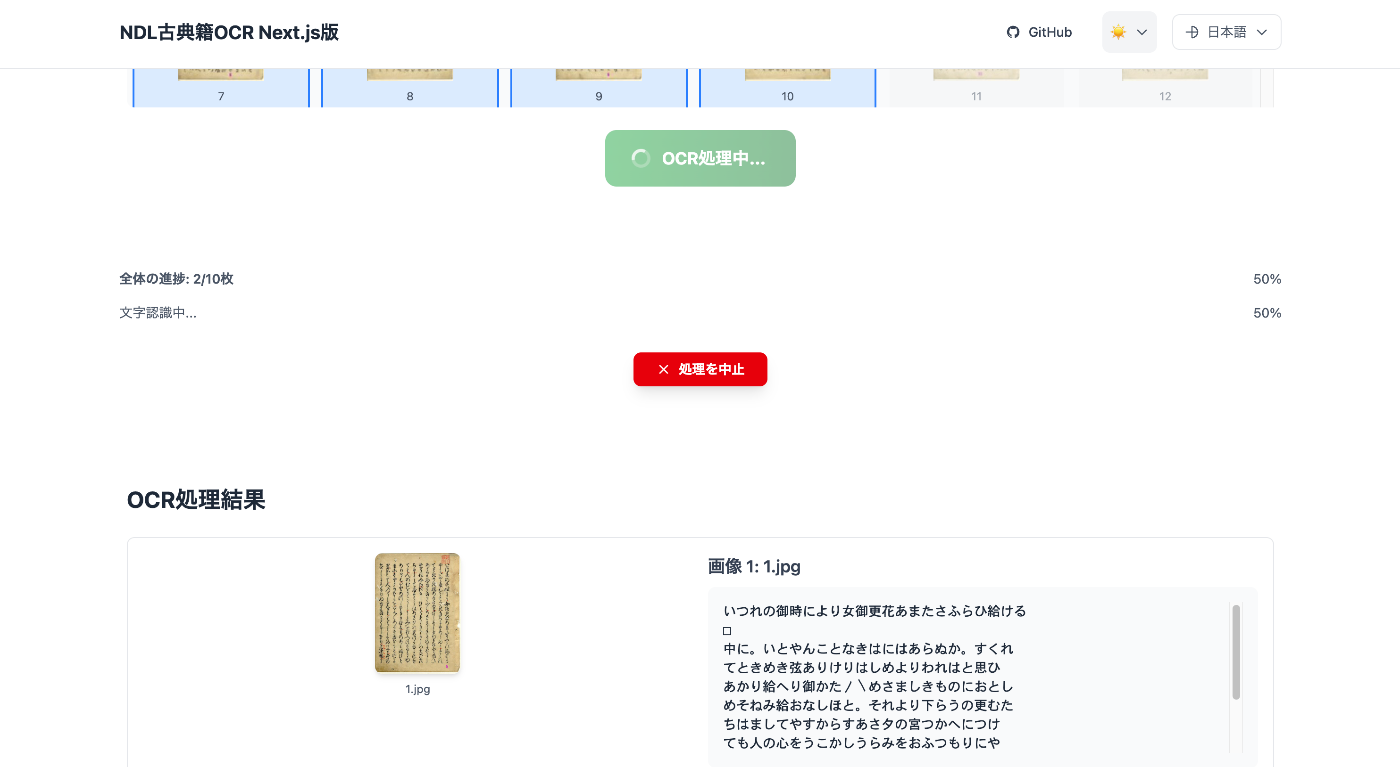
After execution is complete, a download button for the results appears at the bottom of the screen:
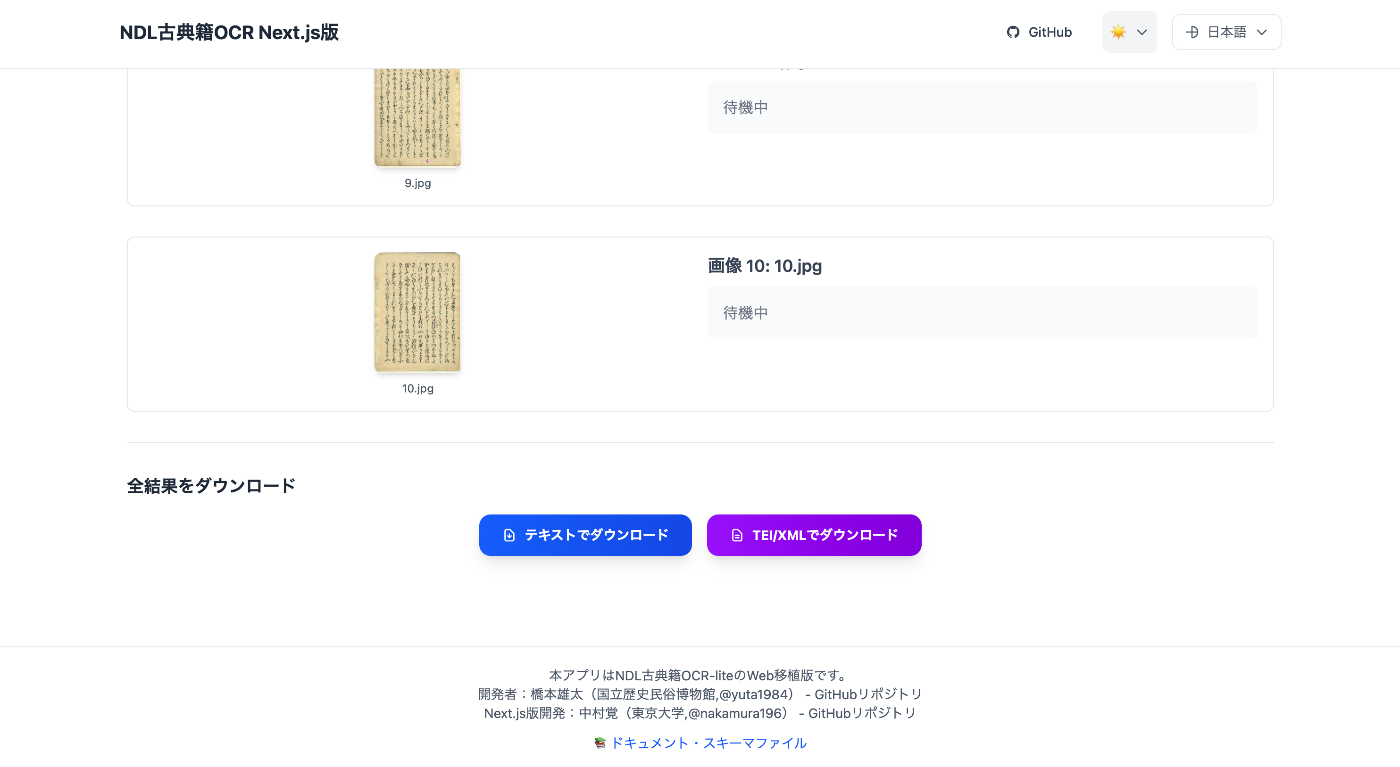
ODD File Creation
When exporting to TEI/XML, I sometimes receive questions about what tags and formats are expected.
To share this format information, I created an ODD (One Document Does it all) file:
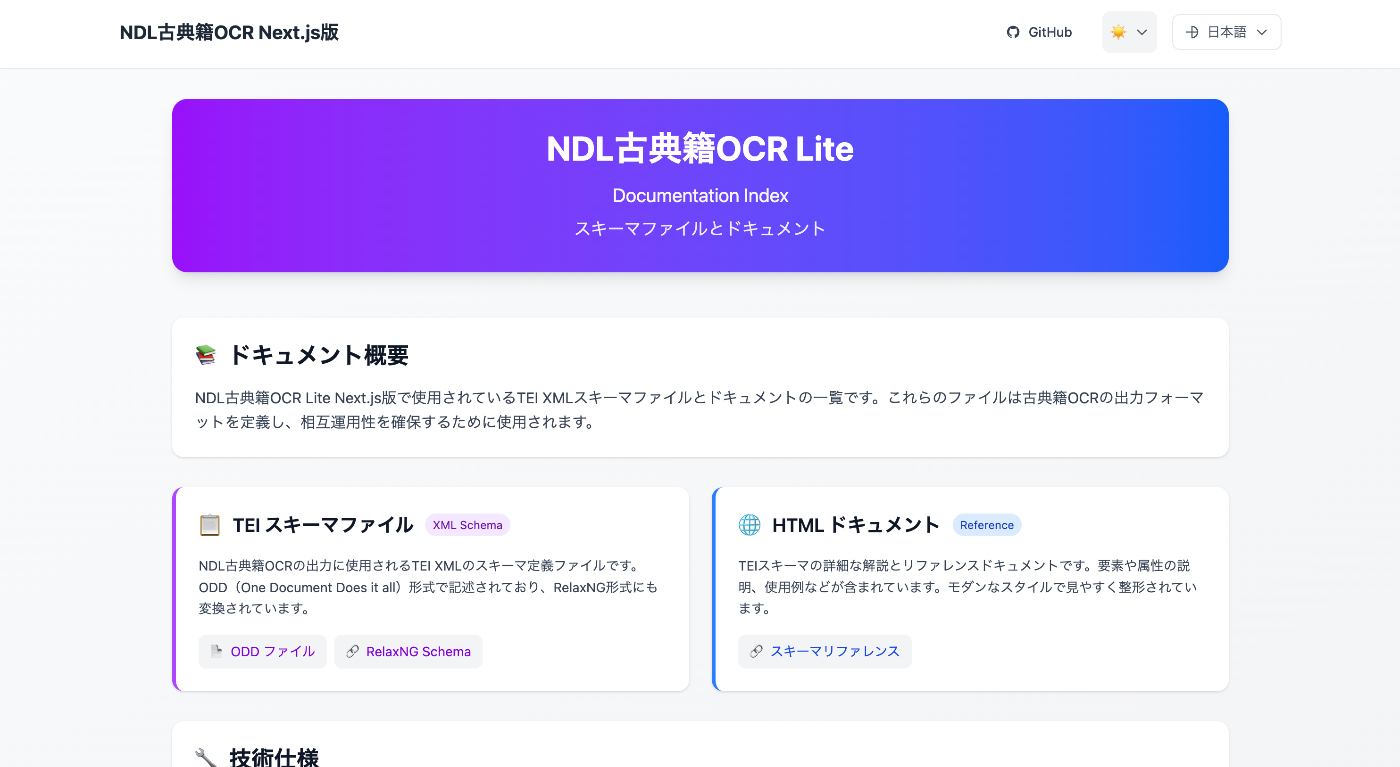
For more information about creating this ODD file, please also refer to the following article:
Additionally, I used the TEIGarage API to create RNG and HTML files. For more about this conversion, please refer to the following article:
While there are still incomplete parts, by taking this approach, it seems possible to publish and share schemas while leveraging the TEI ecosystem.
Previously Created Tools and Future Development Plans
Previous Development
I have developed several tools related to NDL Kotenseki OCR-Lite.
First, I created a Gradio App. While this could be replaced by the officially provided “desktop application”, it is considered useful for purposes such as running OCR on images taken with smartphones or tablets.
Next, as introduced in the following article, I created a web app also using Gradio that takes IIIF manifest files as input and outputs TEI/XML files. While it was useful in connecting IIIF and TEI, there was a limitation that the app was published using Hugging Face’s free tier, making it unable to serve many simultaneous users.
To address these issues, referencing the web version created by @yuta1984, I built an environment that maintains the IIIF-TEI connection functionality while executing OCR processing on the user’s device. This enables multiple people to run processing simultaneously.
Future Outlook
For manual OCR processing, using the official desktop application, @yuta1984’s web app, or the Next.js version web app developed this time should cover most needs.
As a future effort, for batch OCR processing on large numbers of images via API, efficiency can be improved by running OCR processing in parallel across multiple servers. For example, when targeting IIIF manifest files consisting of over 2,000 images, parallel OCR processing is more effective than sequential execution.
To achieve this, as introduced in the following article, I am working on building a scalable OCR processing system using Azure Container Apps.
While there are still incomplete aspects and points to consider, by providing OCR in a serverless environment, the goal is to enable OCR processing on large-scale images.
Summary
I hope this serves as a useful reference for utilizing NDL Kotenseki OCR-Lite.