Overview
I created a similar text search app for the Koui Genji Monogatari. You can try it from the following URL.
https://huggingface.co/spaces/nakamura196/genji_predict
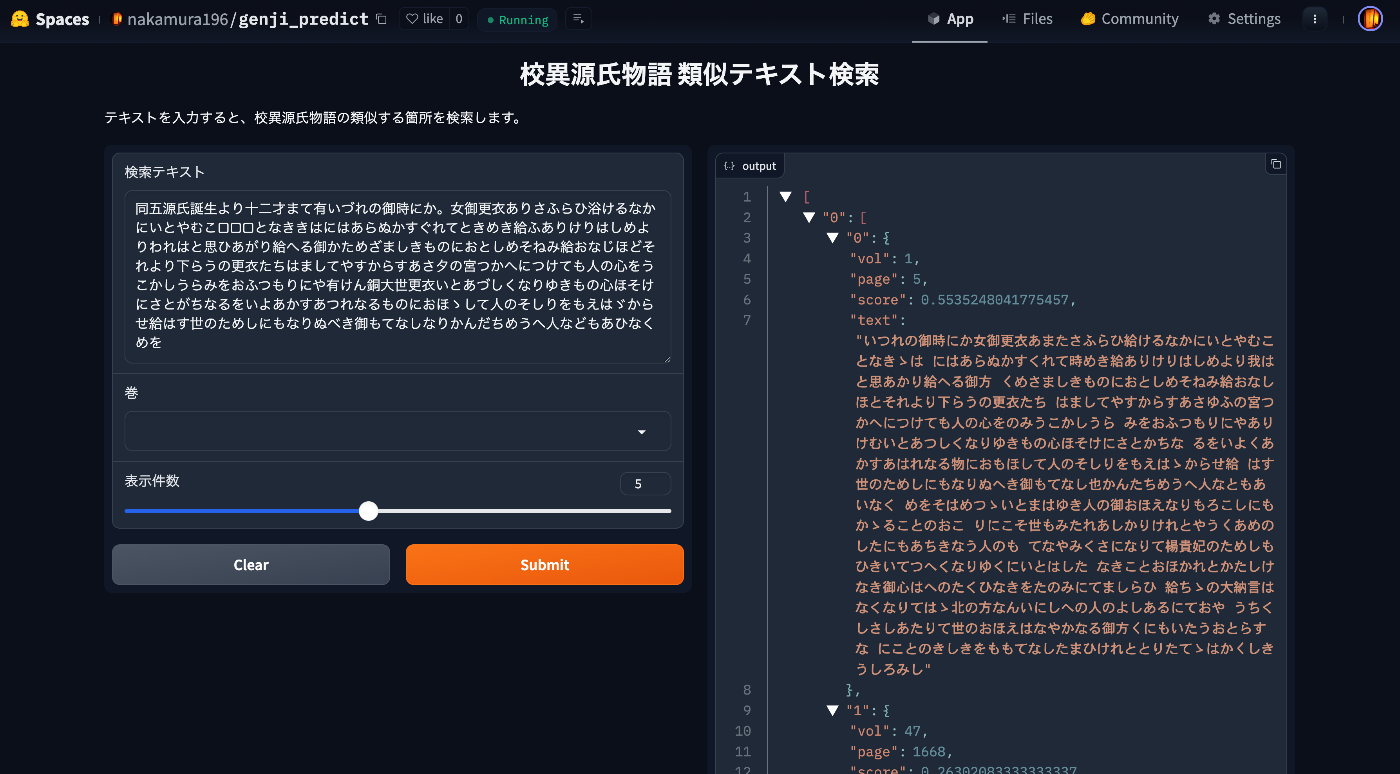
This article introduces how to use the app.
Data
The text data published on the following Koui Genji Monogatari DB is used.
https://kouigenjimonogatari.github.io/
How the App Works
The mechanism is simple: text for each volume and page of the Koui Genji Monogatari is prepared in advance, the edit distance from the input string is calculated, and texts (along with volume and page numbers) with high similarity are returned.
The source code is available at the following link.
https://huggingface.co/spaces/nakamura196/genji_predict/tree/main
Application Example
For instance, in “[Tale of Genji] [4]” (held by the University of Tokyo General Library), multiple volumes are contained within a single IIIF manifest, and it can be difficult for non-specialists to determine which frames belong to which volume.
https://da.dl.itc.u-tokyo.ac.jp/portal/assets/b90bbddc-509d-7c12-0fb9-af409a90a487
By obtaining OCR text for each frame of the above material and querying the app created this time, the estimated volume number for each page is presented, helping identify where volumes change.
OCR
For OCR, NDL Classical OCR-Lite is used.
https://github.com/ndl-lab/ndlkotenocr-lite
The OCR results were corrected and the following TEI/XML was created.
Estimation
Using the above XML file as input, the API of the previously introduced Gradio app is utilized.
The following results are obtained. The key is the frame number, and the value is {volume number}-{page number in the Koui Genji Monogatari}. From these results, it appears that Volume 7 begins at frame 2, and the volume changes at frame 29 or 30 (and again at frame 40 or 41).
Checking frame 30 confirms that the volume has changed.

And frame 41 is as follows.

Summary
It seems that improvements in OCR accuracy for cursive script have enabled various applications. I am grateful to those involved in publishing images, providing institutions, and developing OCR programs.