概要
YOLOv11xと日本古典籍くずし字データセットを用いた文字の検出モデルの構築を行う機会がありましたので、備忘録です。
http://codh.rois.ac.jp/char-shape/
参考
過去に、YOLOv5を用いて同様のことを行いました。以下のspacesで動作デモや学習済みモデルをご確認いただけます。
https://huggingface.co/spaces/nakamura196/yolov5-char
以下は、「国宝 金沢文庫文書データベース」の公開画像に対する適用例です。

YOLOv11を用いることで、文字検出の精度向上を狙うことが目的です。
データセットの作成
「日本古典籍くずし字データセット」をダウンロードし、yoloで求められる形式に整形します。
形式は以下などで確認することができます。
https://github.com/ultralytics/hub/tree/main/example_datasets/coco8
画像のサイズを1280x1280に設定
以下のUltralytics HUBを使用しました。
以下が学習結果です。

テストデータに対して適用したところ、良い精度がでる画像データ(例:「『源氏物語』(東京大学総合図書館所蔵)」)もあれば、
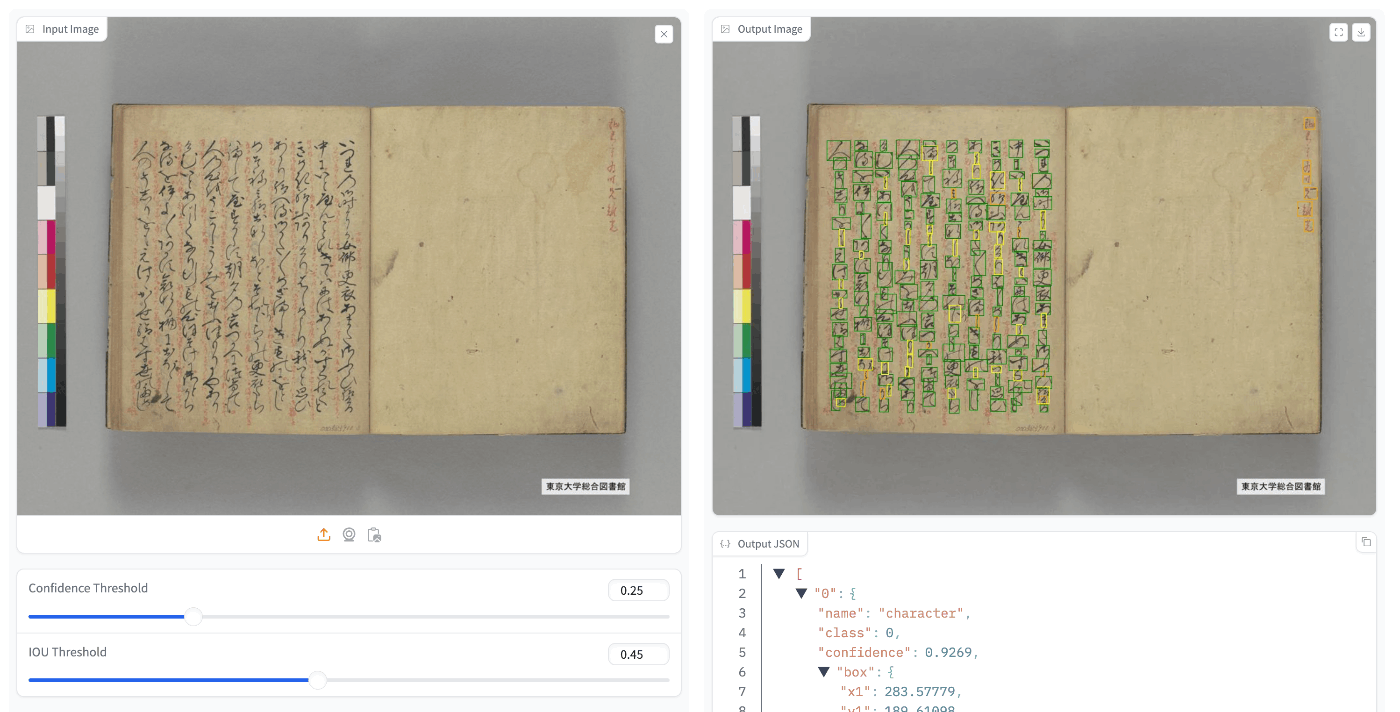
あまり良い精度がでない画像データ(例:「国宝 金沢文庫文書データベース」)もありました。
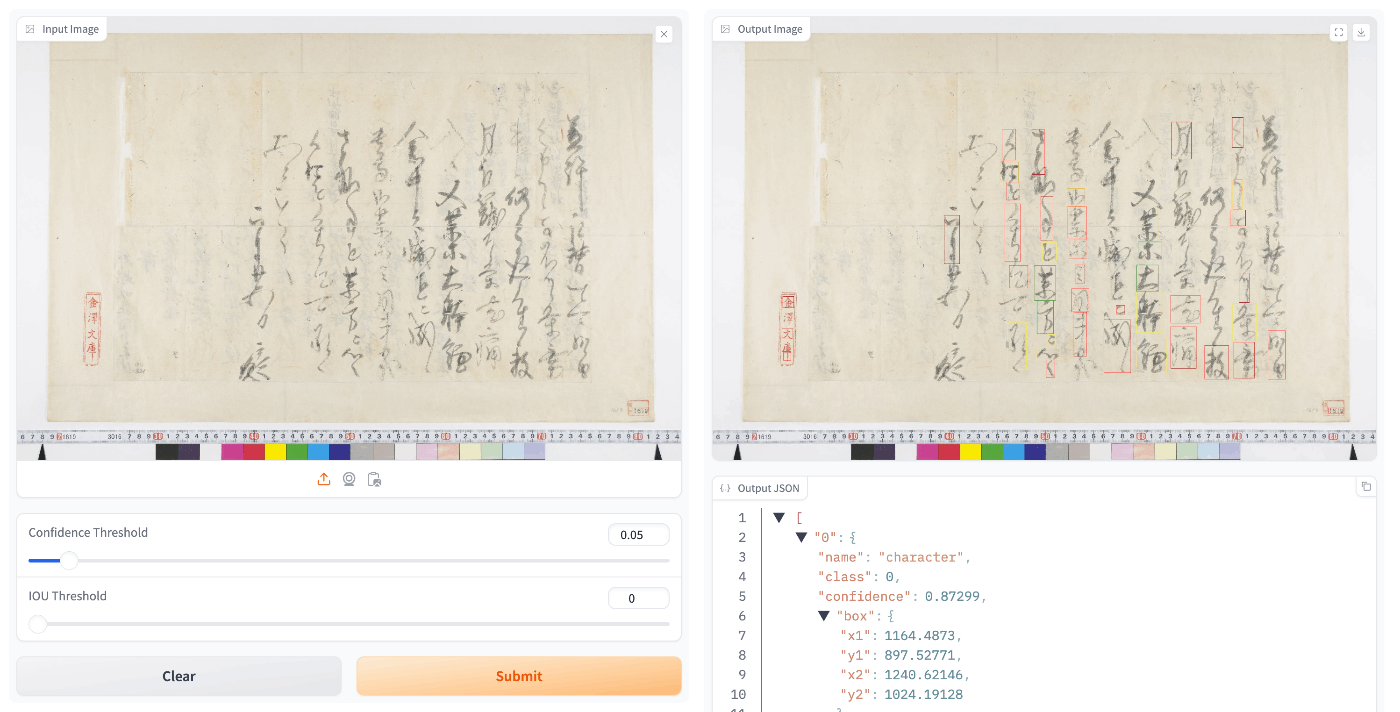
画像のサイズを640x640に設定
エポック数が10の場合
エポック数が10の場合は、エポック数が10の場合、学習が完全に収束していない可能性がありました。
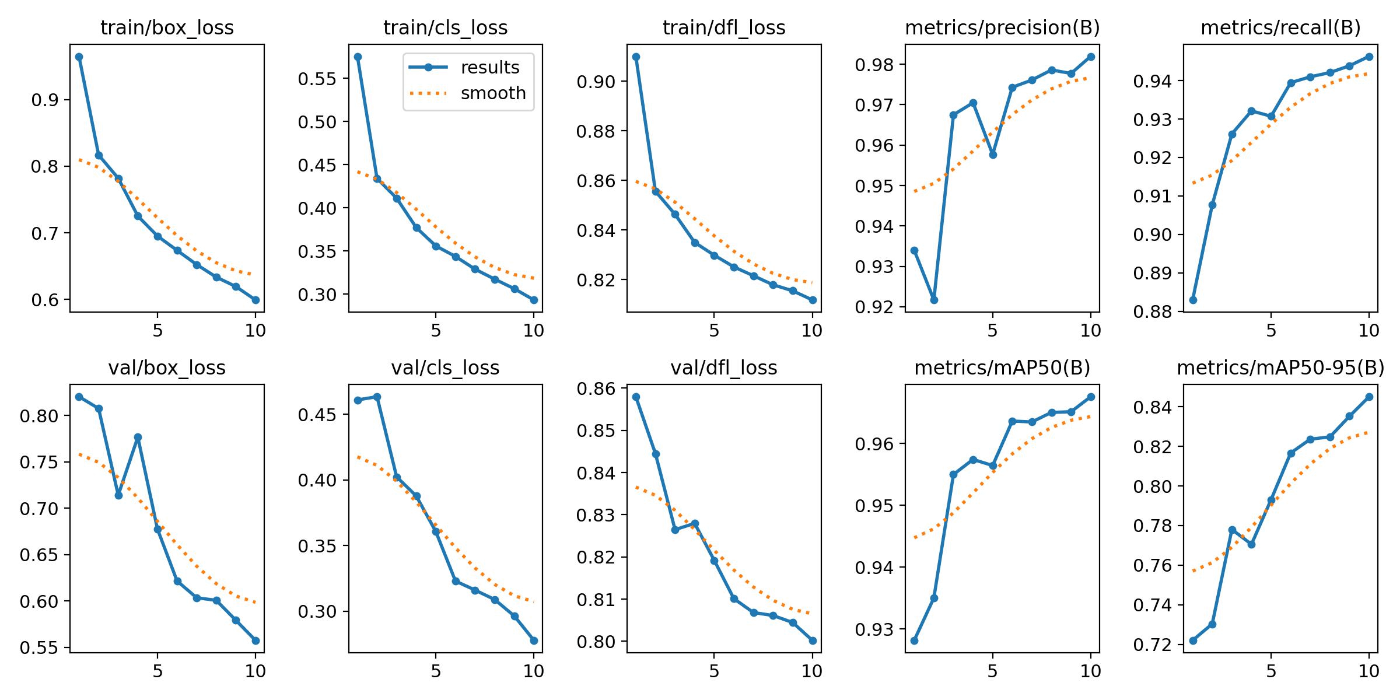
一方、エポック数が少ないにも関わらず、テストデータに対しては、1280x1280のものより良い結果を示すようでした。
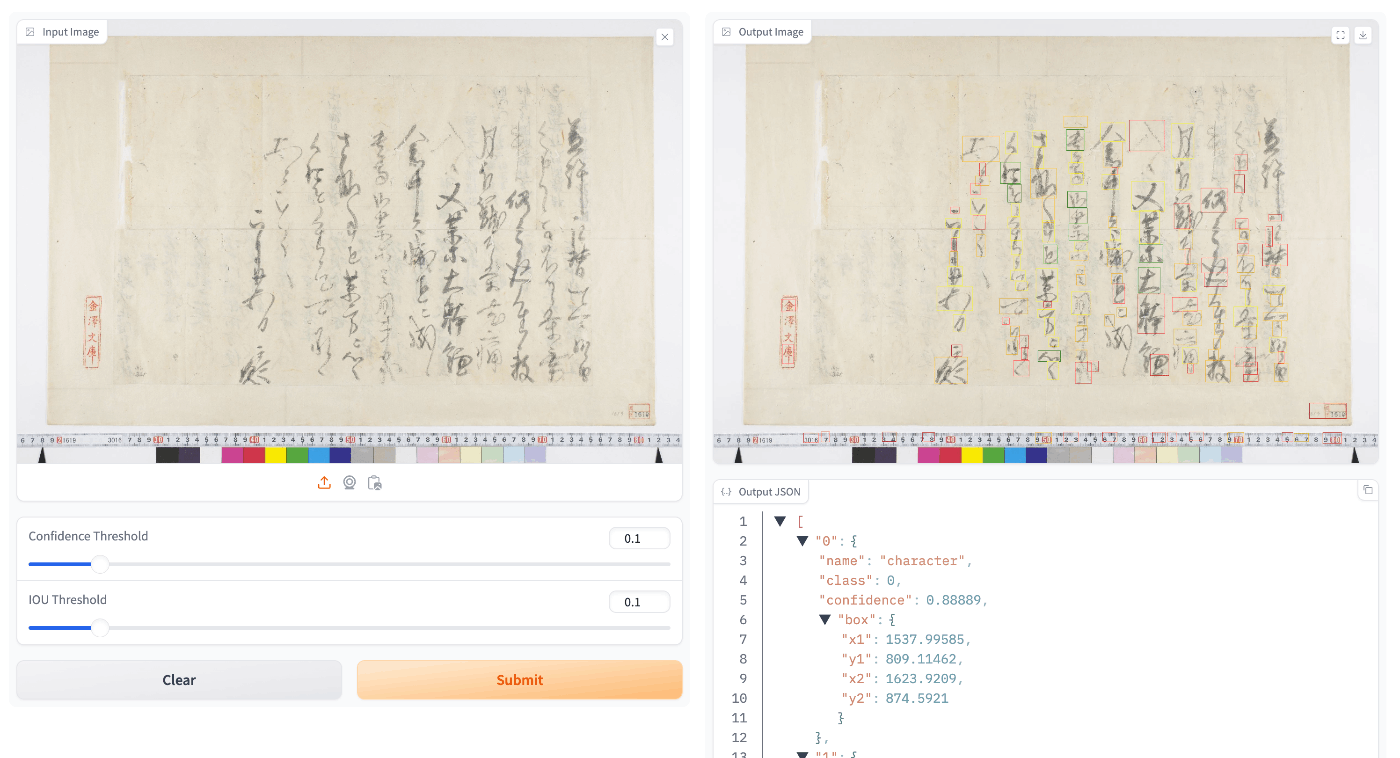
エポック数が100の場合
バッチサイズが16(デフォルト)では、GPUメモリの使用率が低く、32に設定すると、OutOfMemoryErrorになってしまいました。
バッチサイズが24
結果は以下のようになりました。
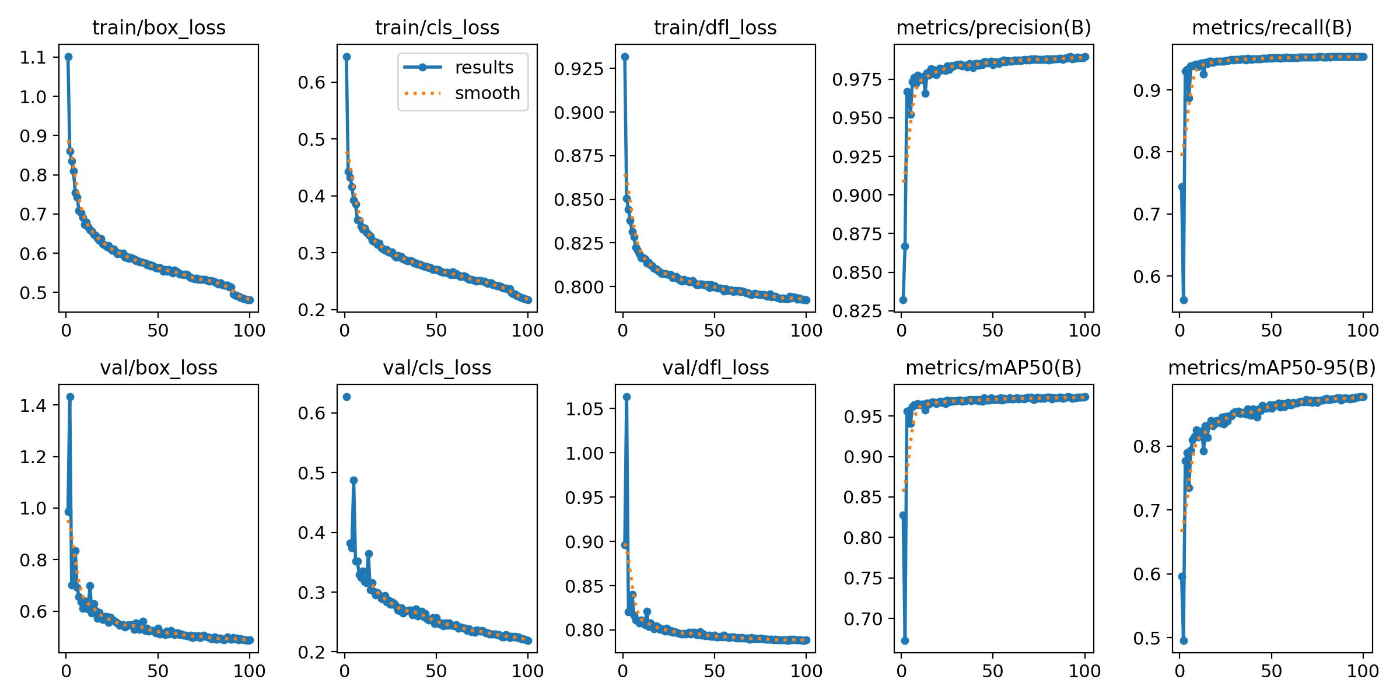
テストデータに対しては、以下の結果になりました。
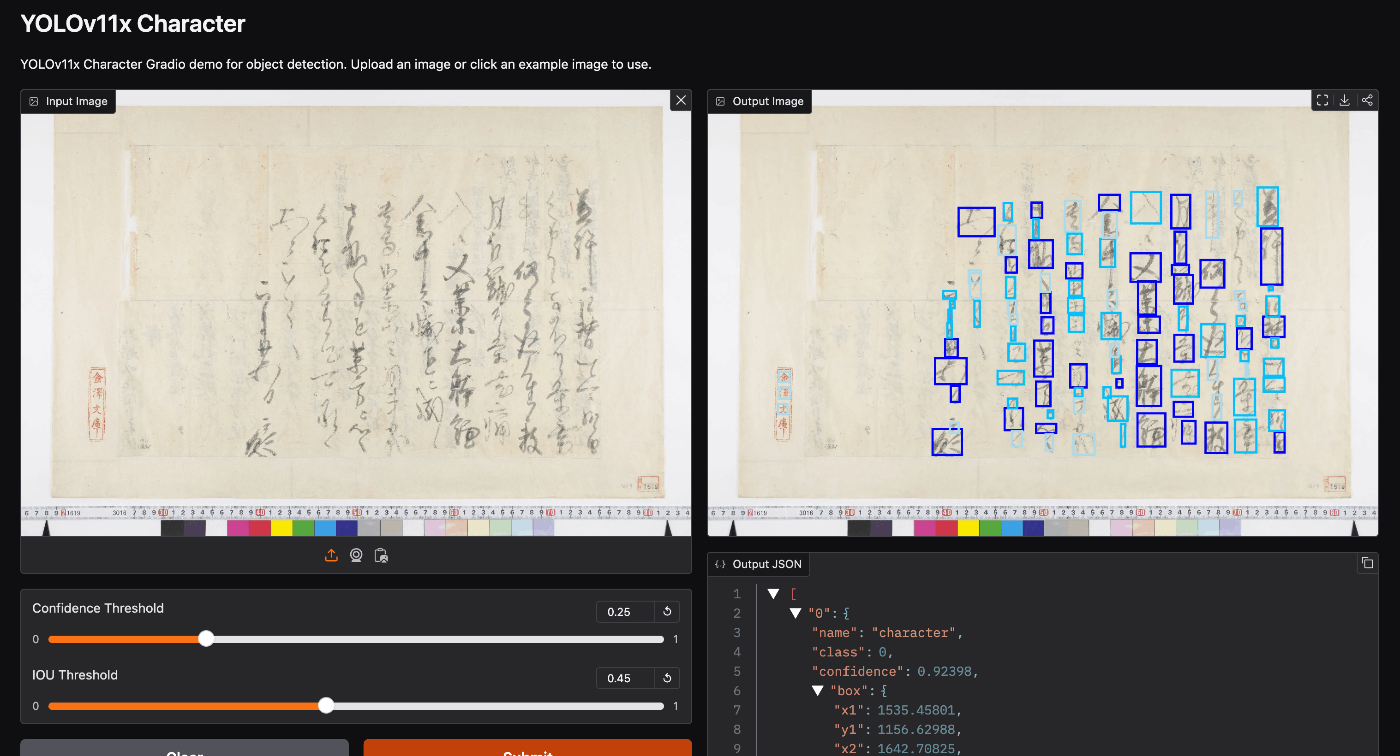
yolov5で構築したモデルと比べて、劇的に精度が向上しているようには見えませんが、画像のサイズを1280x1280に設定したモデルに比べると、検出精度が向上しているように感じられました。
Hugging Face
構築したモデルを用いたスペースを以下で公開しています。
https://huggingface.co/spaces/nakamura196/yolov11x-codh-char
まとめ
mdx.jpや日本古典籍くずし字データセットを用いた物体検出モデルの構築にあたり、参考になりましたら幸いです。