mdx.jpを用いてYOLOv11のクラス分類(くずし字認識)の学習を行う機会がありましたので、備忘録です。
データセット#
以下の「くずし字データセット」を対象にします。
http://codh.rois.ac.jp/char-shape/book/
データセットの作成#
yoloの形式に合致するようにデータセットを整形します。まず、書名ごとに分かれているデータをフラットにマージします。
次に、以下のようなスクリプトにより、データセットを分割します。
結果、1,086,326画像のデータセットが作成されました。
Ultralytics HUBの利用(失敗しました。)#
まず、Ultralytics HUBの利用を考え、データセットにアップロードを試みましたが、以下のようにエラーが出てしまいました。データセットの作成方法に誤りがあるのかなど、原因が分かりかねました。
mdx.jpのオブジェクトストレージへのアップロード#
以下のようなコマンドにより、データセットをオブジェクトストレージにアップロードします。
参考:初期設定#
以下に公式のマニュアルがあります。
https://docs.mdx.jp/ja/index.html#オブジェクトストレージの利用方法例
アップロード
ダウンロード
mdx.jpでの操作#
mdx.jpの1GPUパックを利用します。
以下のようなコマンドにより、データセットをオブジェクトストレージからダウンロードします。
そして、以下のようなスクリプトにより、学習を実行します。
ssh接続が切れても学習を継続できるように、tmuxを使います。
実行後、以下のようなチェックが走ります。
0
「Ultralytics HUB: View model at 」のURLを参照することで、学習経過を確認することができました。
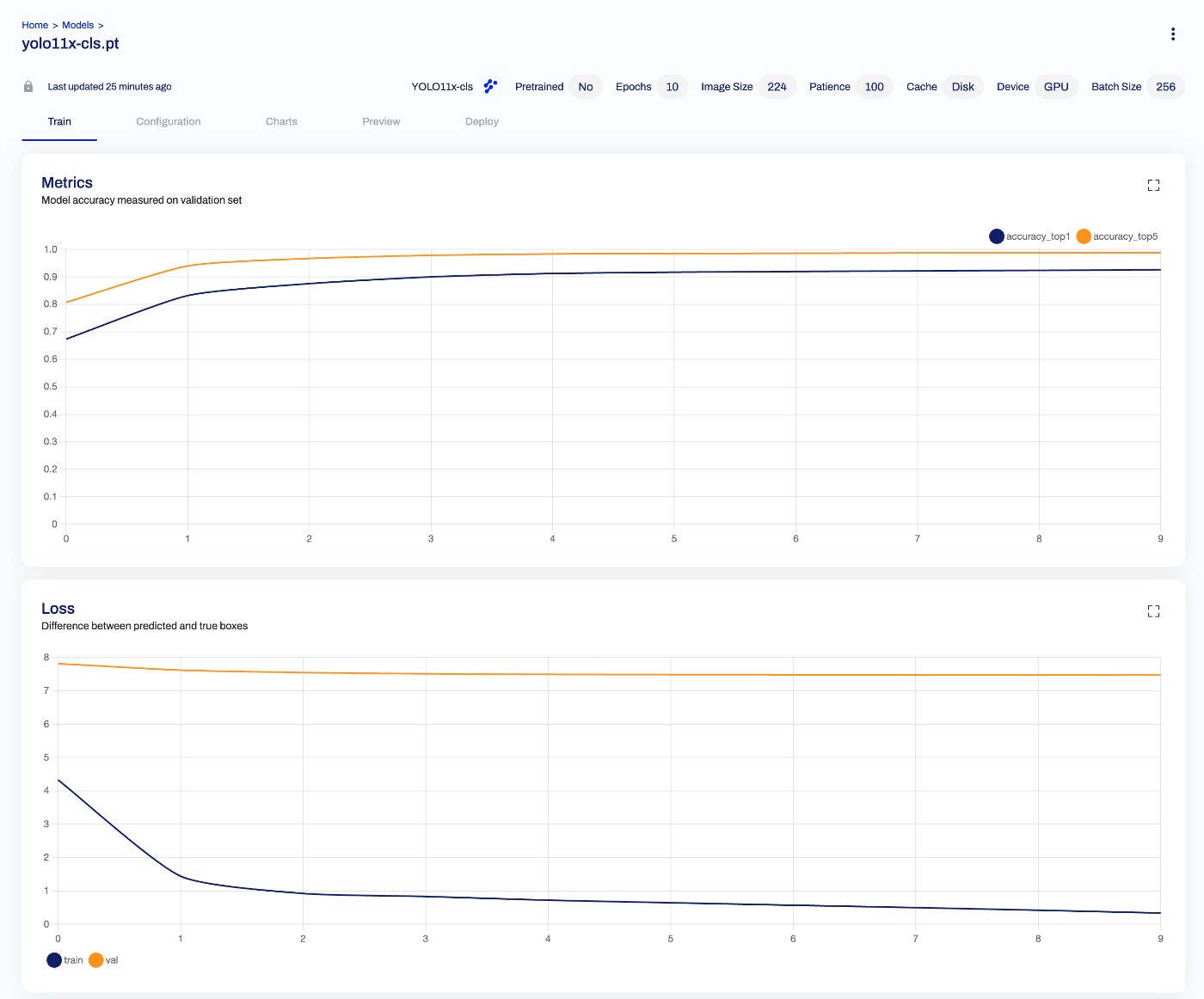
バッチサイズ#
当初、batchサイズを未指定で実行していました。デフォルトは16のようですが、以下のように、GPUのメモリ使用量が低い状態でした。
1
A100の40GBメモリを活かすために、batchサイズを256に変更しました。結果、以下のように1エポックあたりの実行時間を短縮することができました。
2
参考:tmux#
tmuxで現在のセッション一覧を表示する
3
特定のセッションに再接続する
4
tmuxセッションから抜ける(デタッチする)
Ctrl + b を押してから d を押します。
学習結果#
学習結果のモデルは、以下のHugging Faceのスペースからご利用いただけます。
https://huggingface.co/spaces/nakamura196/yolov11x-cls-codh-char
精度については、改善の余地があるかと思いますが、以下のように、正しく結果を返却してくれるケースもありました。
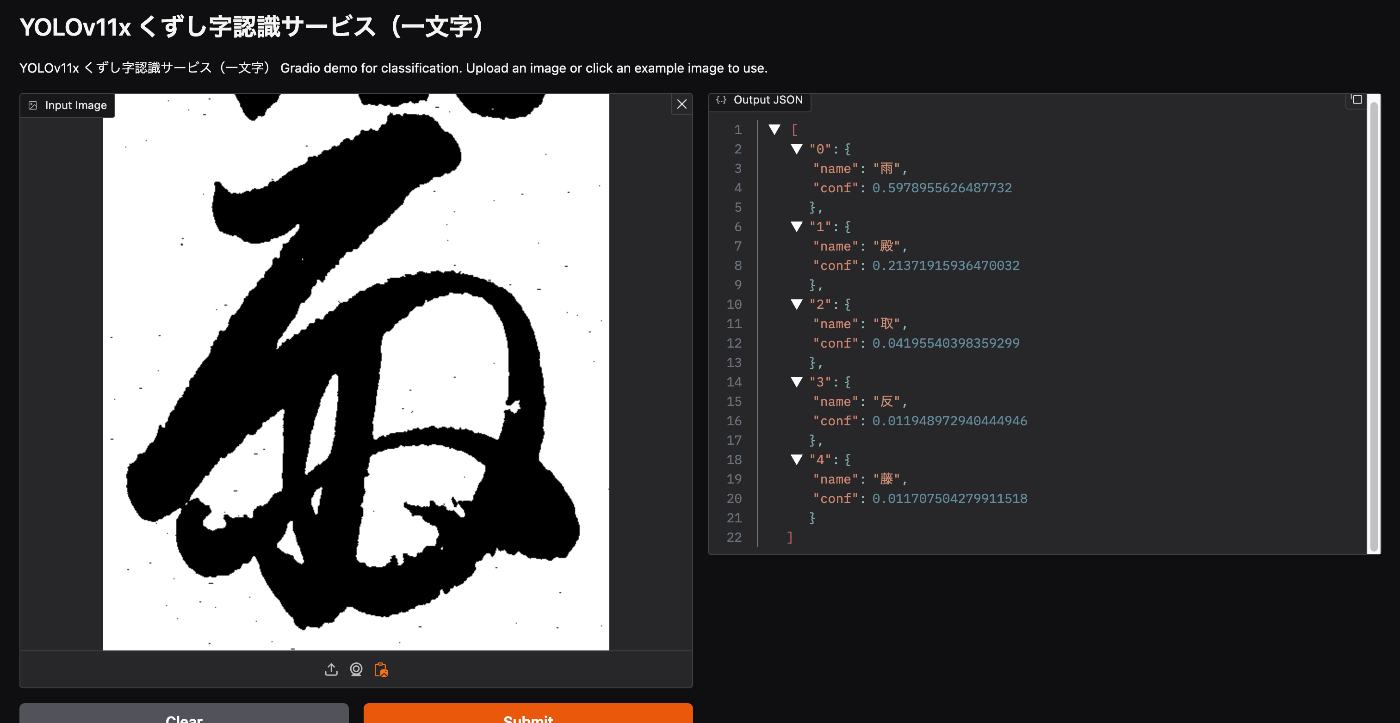
上記では、以下の文字画像を利用しています。
https://mojiportal.nabunken.go.jp/
まとめ#
yolo, mdx.jpなどを使った学習の参考になりましたら幸いです。