校異源氏物語に対する類似テキスト検索アプリを作成しました。以下のURLからお試しいただけます。
https://huggingface.co/spaces/nakamura196/genji_predict
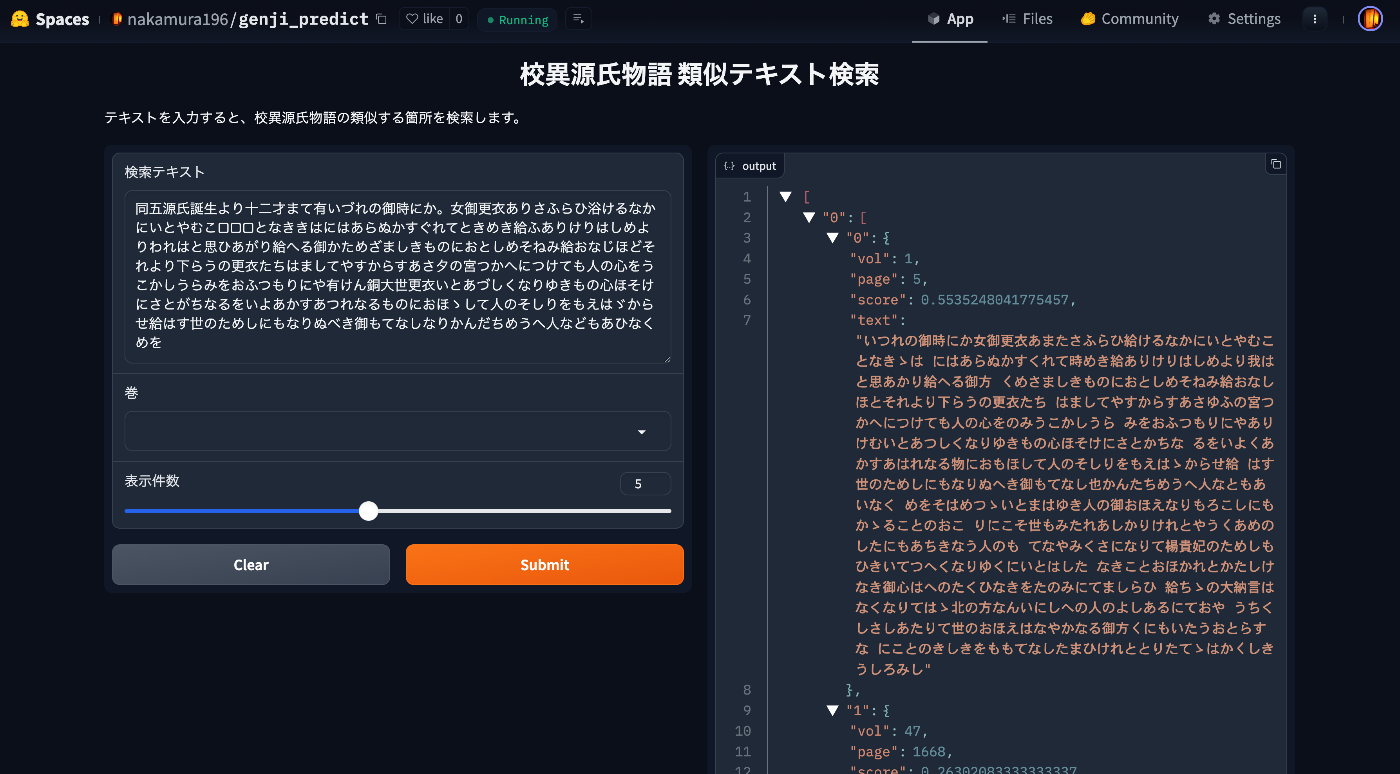
本アプリの使用方法などについて紹介します。
データ#
以下の校異源氏物語DBで公開されているテキストデータを使用します。
https://kouigenjimonogatari.github.io/
アプリの内容#
仕組みは単純で、校異源氏物語の巻毎・ページ毎のテキストを用意しておき、入力された文字列との編集距離を算出し、類似度が高いテキスト(+巻とページ)を返却します。
ソースコードは以下です。
https://huggingface.co/spaces/nakamura196/genji_predict/tree/main
応用例#
例えば、以下の「[源氏物語] [4](東京大学総合図書館所蔵)」では、1つのIIIFマニフェスト内に複数の巻が含まれており、何コマ目から何コマ目までが何巻に属するのか、素人には判断が難しい場合があります。
https://da.dl.itc.u-tokyo.ac.jp/portal/assets/b90bbddc-509d-7c12-0fb9-af409a90a487
そこで、上記に資料に対してコマ毎のOCRテキストを取得し、今回作成したアプリに問い合わせることで、ページ毎に推定される巻数が提示され、巻の変わり目を知る手助けを行うことができます。
OCR#
OCRにあたっては、NDL古典籍OCR-Liteを使用します。
https://github.com/ndl-lab/ndlkotenocr-lite
OCR結果を修正して、以下のようなTEI/XMLを作成しました。
上記のXMLファイルを入力として、先に紹介したGradioアプリのAPIを利用します。
結果、以下のような結果が得られます。キーはコマ数、値は{巻数}-{校異源氏物語のページ数}です。以下の結果から、2コマ目から第7巻が始まり、29または30コマ目(また40または41コマ目)で巻が変わっているように思われます。
実際に30コマ目を確認すると、巻が変わっていることが確認できます。

また41コマ目は以下です。

まとめ#
くずし字に対するOCR精度の向上により、様々な応用が可能になっているように思います。画像の公開および提供機関、OCRプログラムの開発に携わっている方々に感謝いたします。